| La libreria di riferimento di Python |
| La libreria di riferimento di Python |
Il modulo audioop contiene alcune utili operazioni sulla frammentazione del suono. Esso opera su frammenti di suono consistenti di 8, 16 o 32 bit interi firmati, immagazzinati in stringhe Python. Questo č lo stesso formato usato dai moduli al e sunaudiodev. Tutti gli elementi scalari sono interi, a meno che non altrimenti specificato.
Questo modulo fornisce supporto per la codifica u-LAW e Intel/DVI ADPCM.
Alcune delle operazioni piů complicate prelevano soltanto i campioni a 16 bit, altrimenti la dimensione del campione (in byte) č sempre un parametro dell'operazione.
Il modulo definisce le seguenti variabili e funzioni:
| fragment1, fragment2, width) |
1 e 2 o 4. Entrambi i frammenti
dovrebbero avere la stessa lunghezza.
| adpcmfragment, width, state) |
(sample, newstate) dove sample ha la
larghezza specificata in width.
| adpcmfragment, width, state) |
| fragment, width) |
| fragment, width) |
| fragment, width, bias) |
| fragment, width) |
| fragment, reference) |
rms(add(fragment, mul(reference, -F))), č
minimale, per campione restituisce il fattore con il quale si dovrebbe
moltiplicare il riferimento reference per farlo confrontare il
meglio possibile con il frammento fragment. I frammenti
dovrebbero contenere campioni a 2-byte.
Il tempo preso da questa routine č proporzionale a
len(fragment).
| fragment, reference) |
(offset, factor) dove offset č l'offset
(intero) in fragment, da dove inizia la corrispondenza ottimale
e factor č il fattore (in virgola mobile) come per
findfactor().
| fragment, length) |
rms(fragment[i*2:(i+length)*2]) č
massimale. I frammenti dovrebbero contenere entrambi campioni ad
2-byte.
La routine prende il tempo proporzionalmente a
len(fragment).
| fragment, width, index) |
| fragment, width, newwidth) |
| fragment, width, state) |
state č una tupla contenente lo stato del codificatore. Il
codificatore restituisce una tupla
(adpcmfrag, newstate), e newstate dovrebbe
essere passato per la prossima chiamata di lin2adpcm().
Nella chiamata iniziale, None puň essere passato come
state. adpcmfrag č il frammento codificato ADPCM
pacchettizzato con valori 2 4-bit per byte.
| fragment, width, state) |
| fragment, width) |
| fragment, width) |
| fragment, width) |
| fragment, width) |
| fragment, width, factor) |
| fragment, width, nchannels, inrate, outrate, state[, weightA[, weightB]]) |
state č la tupla contenente lo stato del convertitore. Il
convertitore restituisce una tupla
(newfragment, newstate), e newstate) dovrebbe
essere passato per la prossima chiamata di ratecv(). La
chiamata iniziale dovrebbe passare None per state.
Gli argomenti weightA e weightB sono parametri per un
semplice filtro digitale ed il loro valore predefinito č
rispettivamente 1 e 0.
| fragment, width) |
| fragment, width) |
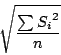
| fragment, width, lfactor, rfactor) |
| fragment, width, lfactor, rfactor) |
| fragment, width) |
Notare che operazioni come mul() o max() non fanno distinzione tra frammenti mono e stereo, per esempio tutti i campioni sono trattati allo stesso modo. Se questo č un problema, il frammento stereo dovrebbe essere prima diviso in due frammenti mono, e dopo ricombinato. Qui c'č un esempio di come fare questo:
def mul_stereo(sample, width, lfactor, rfactor):
lsample = audioop.tomono(sample, width, 1, 0)
rsample = audioop.tomono(sample, width, 0, 1)
lsample = audioop.mul(sample, width, lfactor)
rsample = audioop.mul(sample, width, rfactor)
lsample = audioop.tostereo(lsample, width, 1, 0)
rsample = audioop.tostereo(rsample, width, 0, 1)
return audioop.add(lsample, rsample, width)
Se si usa il codificatore ADPCM per costruire pacchetti di rete e volete che il vostro protocollo sia indipendente (per esempio per tollerare la perdita di pacchetti), non dovreste solamente trasmettere i dati ma anche lo stato dei dati. Notare che si potrebbe inviare lo stato iniziale, initial, (quello passato a lin2adpcm()) attraverso il decodificatore e non lo stato finale (come restituito dal codificatore). Se si vuole usare struct.struct() per conservare lo stato in forma binaria, si puň codificare il primo elemento (il valore previsto) a 16 bit e il secondo (l'indice delta) in 8.
I codificatori ADPCM non sono mai stati confrontati con altri codificatori ADPCM, ma solamente con sé stessi. Potrebbe benissimo essere che abbia interpretato male lo standard, in questo caso non saranno interoperabili con i rispettivi standard.
Le routine find*() possono sembrare un po' buffe a prima vista. Sono significanti per fare da echo alle cancellazioni. Un modo ragionevolmente veloce per fare questo č prendere il pezzo piů energetico del campione di output, posizionarlo nel campione di input e sottrarre l'intero campione di output dal campione di input:
def echocancel(outputdata, inputdata):
pos = audioop.findmax(outputdata, 800) # one tenth second
out_test = outputdata[pos*2:]
in_test = inputdata[pos*2:]
ipos, factor = audioop.findfit(in_test, out_test)
# Optional (for better cancellation):
# factor = audioop.findfactor(in_test[ipos*2:ipos*2+len(out_test)],
# out_test)
prefill = '\0'*(pos+ipos)*2
postfill = '\0'*(len(inputdata)-len(prefill)-len(outputdata))
outputdata = prefill + audioop.mul(outputdata,2,-factor) + postfill
return audioop.add(inputdata, outputdata, 2)
| La libreria di riferimento di Python |